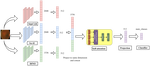
In this study, we assess the quality of ImageNet self-supervised pretrained features in four selected medical image classification tasks. We demonstrate that feature extractors which were pretrained using SwAV, SimCLR or DINO consistently yield richer embeddings on the downstream tasks compared to a superviesed pretrained baseline model. Among all self-supervised techniques, DINO outperforms the other methods on the majority of datasets and subtasks. Furthermore, we show that the representations from each individual pretrained model encode complementary information which can be fused to yield even more meaningful features. To that end we propose Dynamic Visual Meta-Embedding (DVME), a model-agnostic meta-embedding approach. Our experiments indicate that DVME outperforms the best single model baseline on numerous tasks. As a model-agnostic approach, DVME is not limited to SwAV, SimCLR or DINO. With slight modifications other models can be combined using DVME to generate enriched representations.